When this relaxed city on the Rhine became West Germany’s ‘temporary’ capital in 1949 it surprised many, including its own residents. When in 1991 a reunited German government decided to move to Berlin, it shocked many, especially its own residents.
A generation later, Bonn is doing just fine, thank you. It has a healthy economy and lively urban vibe.
Following Olli’s recommendation I took a crack at Andrew Ng’s machine learning course on Coursera. It’s for free, it’s well-designed and taught and I highly recommend it. I’d like to share my codes for the course, but I think that would be against the spirit of such an online class.
Some observations:
It’s an introductory course, so there are no proofs. The focus is on graphical intuition, implementing the algorithms in Octave/Matlab and the practicalities of large-scale machine learning projects.
The goal is not to accurately estimate the \(\beta\) and the uncertainty around it, but to be precise in predicting the \(\hat{y}\) out of sample. (See also here.)
The course is refreshingly different from what we normally study and I think best taken not as a substitute, but as a complement to econometrics classes.
It uses a different vocabulary:
Machine learning
Econometrics
example
observation
(to) learn
(to) estimate
hypothesis
estimation equation
feature/input
variable
output/outcome
dependent variable
bias
constant/intercept
bias (yeah, twice 🤔)
bias
Linear regression is introduced through the cost function and its numerical minimization. Ng shows the analytical solution on the side, but he adds that it would only be useful in a “low-dimensional” problem up to 10,000 or so variables.
I liked the introduction to neural networks in week 4 and the explanation of them as stacked logical operators.
Insightful discussion of how to use training and cross-validation set errors plotted against the regularization parameter and against the number of observations to identify whether bias or variance is a problem.
The video on error analysis made me realize that in my patent project I had spend a very large amount of time thinking about appropriate error metrics, but little time actually inspecting the mis-classified patents.
In a presentation I once attended, Tom Sargent said:
A little linear algebra goes a long way.
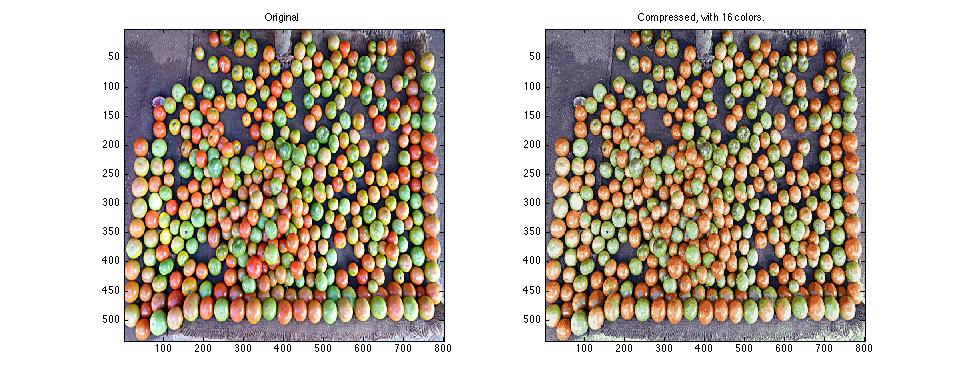
Similarly here: Only doing a little clustering, for example, we can compress the file size of this image by a factor of six, but preserve a lot of the information (exercise 7):
Figure: Image compression with PCA
I hadn’t previously thought of dimension reduction as a debugging method: If you get thousands of features from different sources and you’re not sure if some might be constructed similarly, then dimension reduction weeds out the redundant features.
Time series data is suspiciously missing from the course.
[…] [I]t’s not who has the best algorithm that wins. It’s who has the most data.
And he recommends asking:
How much work would it be to get 10x as much data as we currently have?
Ng stresses again and again that our intuitions on what to optimize often lead us astray. Instead we should plot error curves, do error analysis and look at where the bottlenecks in the machine learning pipepline are.
I also liked the discussion of using map-reduce for parallelization at the end of the class. Hal Varian also discussed that here.
They held a survey with 20,000 professors and 20,000 PhD students in Germany.
There are currrently 33,154 professors in Germany that can graduate a PhD student (“Promotionsrecht”).
The immense number of PhD students (“Promovierende”) is 196,200 of which 111,400 are enrolled at an university. And 99% of those finishing their PhDs are those that are enrolled at an university. (These numbers are obviously inflated by German peculiarities such as counting medical doctorates as PhDs.)
11% of professors have no PhD students, 50% have 1-5 students and 3 percent have more than 20 PhD students. The average is 6 students per professor and that ratio is highest for the engineering subjects.
44% (\(= \frac{87,000}{196,200}\)) of PhD students are women.
The modal age is 29.
15% are non-German.
23% of students are in structured programs, 23% of students are doing a cumulative dissertation (economics PhD-style).
Okasha explains the difference between deductive and inductive reasoning. A deductive argument follows from its assumptions. An inductive argument is one where you have to reason about new unseen things.
At the root of Hume’s problem is the fact that the premisses of an inductive inference do not guarantee the truth of its conclusion.
Philosophers have responded to Hume’s problem in literally dozens of different ways; this is still an active area of research today.
For inductive reasoning to help us make predictions about the future, we need a new assumption. We have to take as given that along some lines things will remain the same.
This assumption may seem obvious, but as philosophers we want to question it. Why assume that future repetitions of the experiment will yield the same result? How do we know this is true?
A good model is one that’s not too crude about what it accepts about nature’s constancy. If you assume that business cycles just mechanically happen every seven or so years, then that’s fairly crude.
Karl Popper thought that scientists should only argue deductively. We all know Karl Popper and we cite him when we say that theories have to be falsifiable. But philosophy of science didn’t stop with Popper. In particular, Popper’s theory of progress in science doesn’t capture what actually happens:
In general, scientists do not just abandon their theories whenever they conflict with the observational data. […] Obviously if a theory persistently conflicts with more and more data, and no plausible ways of explaining away the conflict are found, it will eventually have to be rejected. But little progress would be made if scientists simply abandoned their theories at the first sign of trouble.
Most philosophers think it’s obvious that science relies heavily on inductive reasoning, indeed so obvious that it hardly needs arguing for. But, remarkably, this was denied by the philosopher Karl Popper, […]. Popper claimed that scientists only need to use deductive inferences.
The weakness of Popper’s argument is obvious. For scientists are not only interested in showing that certain theories are false.
In contrast, Thomas Kuhn speaks of paradigm changes:
In short, a paradigm is an entire scientific outlook – a constellation of shared assumptions, beliefs, and values that unite a scientific community and allow normal science to take place.
But over time anomalies are discovered – phenomena that simply cannot be reconciled with the theoretical assumptions of the paradigm, however hard normal scientists try. When anomalies are few in number they tend to just get ignored. But as more and more anomalies accumulate, a burgeoning sense of crisis envelops the scientific community. Confidence in the existing paradigm breaks down, and the process of normal science temporarily grinds to a halt.
In Kuhn’s words, ‘each paradigm will be shown to satisfy the criteria that it dictates for itself and to fall short of a few of those dictated by its opponent’.
Karl Popper is normative, “How should science be done?”, while Thomas Kuhn is descriptive, “How is science done?”
Okasha concludes,
In rebutting the charge that he had portrayed paradigm shifts as non-rational, Kuhn made the famous claim that there is ‘no algorithm’ for theory choice in science. […] Kuhn’s insistence that there is no algorithm for theory choice in science is almost certainly correct.
The moral of his story is not that paradigm shifts are irrational, but rather that a more relaxed, non-algorithmic concept of rationality is required to make sense of them.
Kuhn’s idea of “theory-ladenness” of data is interesting. Kuhn says that this makes comparisons between theories difficult or impossible. That’s probably exaggerated, but in economics, many of the things we measure (like GDP) are abstract concepts and theory guides how we measure it.
Noah Smith argues that inflation has low costs and central banks should therefore sometimes trade-off higher inflation against better GDP performance. And Olivier Blanchard has made the case to raise the inflation target above the current 2%, to increase the distance to the zero lower bound.
Yet in the mind of many people there’s no place for inflation. People have “money illusion”, so they fail to adjust nominal values for overall price changes and feel richer or poorer when really they ‘re not. Inflation is seen as a bad thing and George Akerlof and Robert Shiller write:
Inflation itself, particularly when it is increasing, can ultimately create a negative effect on the atmosphere of an economy, akin to the effect of broken windows and graffiti on a city. These lead to a breakdown in the sense of civil society, in the sense that all is right with the world. (p65, “Animal Spirits“)
For my bachelor thesis, I read Barry Eichengreen’s “Globalizing Capital”. He explains how modern economies changed after World War I. Larger firm conglomerates and unionization made wages of workers less flexible. And this downward wage rigidity was a problem during the Great Depression.
Nominal rigidities are the reason that monetary policy works at all. If prices and wages were flexible, then when the central bank doubles the money in circulation, all prices would also double immediately. So, I thought, the solution is to index all prices. If inflation from this year to the next is 2 percent, then your wage, your rent and every other price should automatically rise by 2 percent. And if for some reason the aggregate price level falls, then all these prices would also adjust downwards.
But indexing all prices is not workable and people wouldn’t accept it. And because money isn’t neutral, there is a role for intentional monetary policy. One of the most important effects of higher inflation is that, if wages adapt slowly, real wages fall for a while. So it’ll be cheaper for firms to hire people and they’ll be more willing to do so.
Economists are quick to prescribe other people economics lessons, but understanding inflation and the difference between nominal and real values is a basic skill that I wish more people would have.
In “The Berlin Stock Exchange in Imperial Germany - a Market for New Technology?”, (pdf) Sibylle Lehmann-Hasemeyer and Jochen Streb look at how well the financial market assessed firm innovativeness in pre-1913 Germany. They show that the stock market guessed well which companies would continue to innovate after they went public.
Between 1892 and 1919, 474 companies started trading their shares on the Berlin stock exchange. The authors take the change in the price of the stock on its first day of trading as an measure of “underpricing” which indicates how much asymmetric information there is in the markets.
Underpricing is bad for a firm, as it receives fewer funds than if it had sold its shares at a higher price. For example, Google went to great lengths to determine a good price. And with more capital the firm can invest more into research and so be granted more patents later. So one has to argue that this effect can’t be strong enough to lead to reverse causality.
Lehmann-Hasemeyer and Streb control for what investors knew at the time of the initial public offering (IPO) about how innovative firms already were. For this, they count the number of patents a firm had been granted before. So patents are a proxies for the innovativeness of a firm. This is an example of using patents as “inputs” to the technological process, in Zvi Griliches’ wording.
Research is a risky activity, so there might be more asymmetric information in the price for stocks of research-intensive companies. But that’s not what they find as there was little underpricing in the stocks of firms that continued to be innovative after the IPO. This might be due to the screening of banks:
Overall, German universal banks seemed to be well informed about the market value of firms that planned to go public. The comparatively low underpricing that occurred at the Berlin stock exchange during Germany’s high industrialization might therefore indicate that investors’ uncertainty was rather small because they knew that banks brought only those firms to the market that met certain minimum quality requirements.
They conclude that investors must have had more information than patent counts:
[Investors] were capable of distinguishing between permanently innovative firms and firms with sharply declining innovativeness (Buddenbrooks), even though both types of firms looked very similar at the date of the IPO with respect to their patent history. This observation implies that pure patent counts that are often used in cliometric studies of innovation might not be a good proxy for the knowledge that was available at the date of an IPO.
The paper is forthcoming in the American Economic Review.
There’s a species of books in which a commonly-held view by established researchers is criticized by someone from outside the profession and supposedly shown to be wrong.
There’s nothing wrong with people who are not scientists writing about science. But two lines of argument in those books aren’t convincing:
The outsider does not have to hold to establish views to advance and has therefore figured out something that people within the profession have missed or aren’t allowed to say.
The respective branch of science is not an experimental science and can therefore not establish causality.
The first is rarely the case. Science isn’t a closed environment where you’re not allowed to speak your mind. Dani Rodrik writes in his “Ten Commandments for Noneconomists”:
[Nine.] If you think all economists think alike, attend one of their seminars.
[Ten.] If you think economists are especially rude to noneconomists, attend of one of their seminars.
And the second argument is misleading. How did we figure out that the Earth orbits the Sun or that smoking causes cancer? Not through experiments. Also, if scientists can’t claim to identify causality, why should the outsider?
In the “The Nurture Assumption” (which is else an interesting book), Judith Rich Harris writes (added emphasis):
[Socialization research] is a science because it uses some of the methods of science, but it is not, by and large, an experimental science. To do an experiment it is necessary to vary one thing and observe the effects on something else. Since socialization researchers do not, as a rule, have any control over the way parents rear their children, they generally cannot do experiments. Instead, they take advantage of existing variations in parental behavior. They let things vary naturally and, by systematically collecting data, try to to find out what things vary together. In other words, they do correlational studies.
Tom Wolfe’s book (which I haven’t read) sounds a lot like that as well:
Evolution, [Tom Wolfe] argues, isn’t a “scientific hypothesis” because nobody’s seen it happen, there’s no observation that could falsify it, it yields no predictions and it doesn’t “illuminate hitherto unknown or baffling areas of science.” Wrong - four times over.
I like Jerry Coyne’s final take-down:
Somewhere on his mission to tear down the famous, elevate the neglected outsider and hit the exclamation-point key as often as possible, Wolfe has forgotten how to think.